Automating Mail Processing for a Workers’ Compensation Law Firm
Author

Pavel Tolstyko
Developer
As a developer, I love solving challenges and building solutions that make a difference. Keeping up with the latest tech trends helps me to merge creativity with technical skills to deliver great products.
Main tools
Introduction
Our project aimed to improve the mail processing system for a law firm specializing in Workers’ Compensation cases. By implementing cutting-edge automation solutions, we significantly reduced manual labor, increased efficiency, and minimized errors in document handling.
Business Challenge
The law firm was struggling with an overwhelming volume of daily physical mail, which required extensive manual processing. This labor-intensive process included:
- Scanning hundreds of letters
- Manually classifying and tagging documents
- Renaming files for easy identification
- Forwarding documents to appropriate attorneys
This process was time-consuming, prone to errors, and resource-intensive, impacting the firm’s operational efficiency and client service quality.
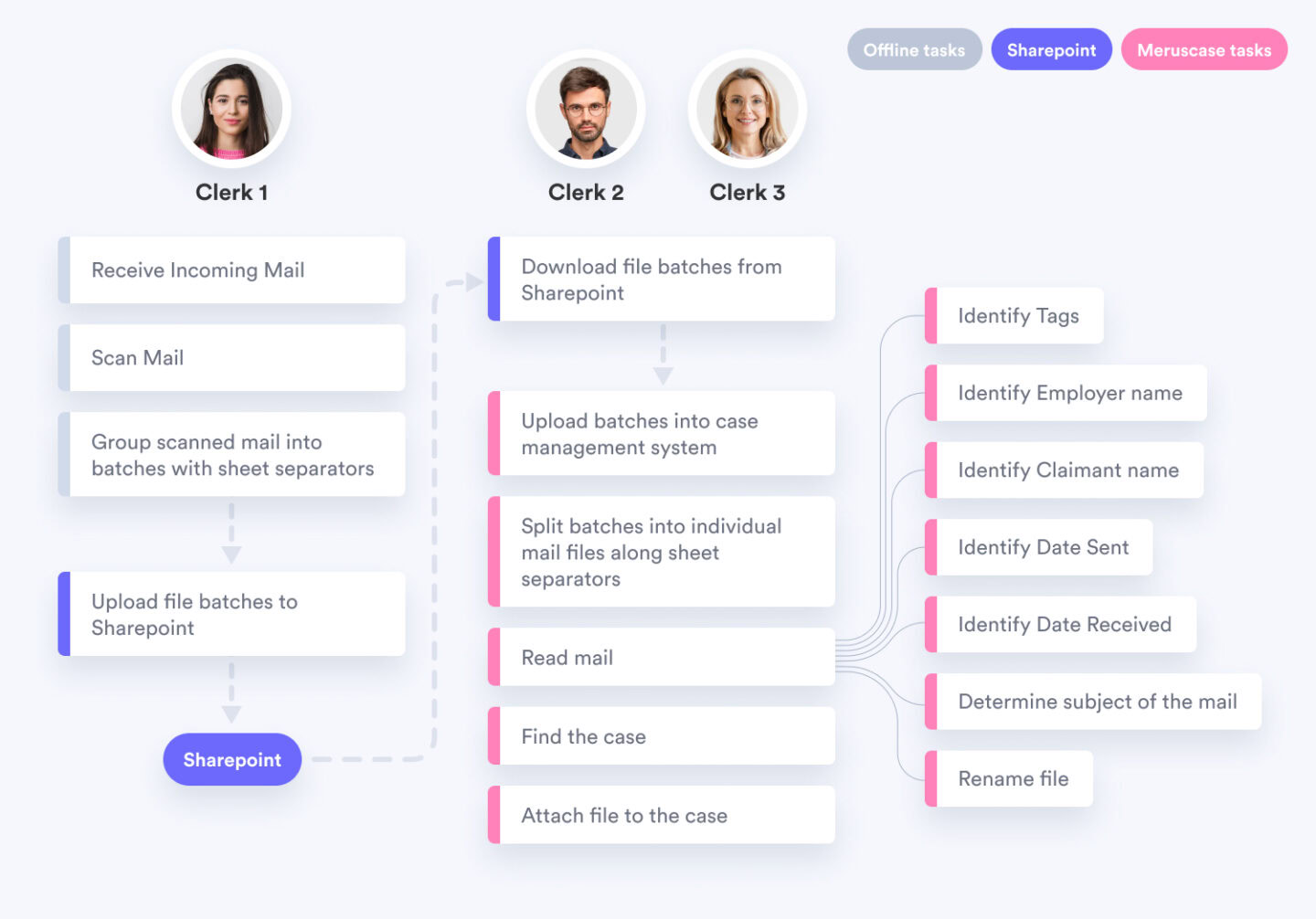
Our Solution
We developed a comprehensive automation system that leverages machine learning and artificial intelligence to streamline the entire mail processing workflow. Key components of our solution include:
- Text Recognition (OCR)
- Automated document classification
- Intelligent file naming
- Information extraction using Large Language Models (LLMs)
- Automated routing to attorneys
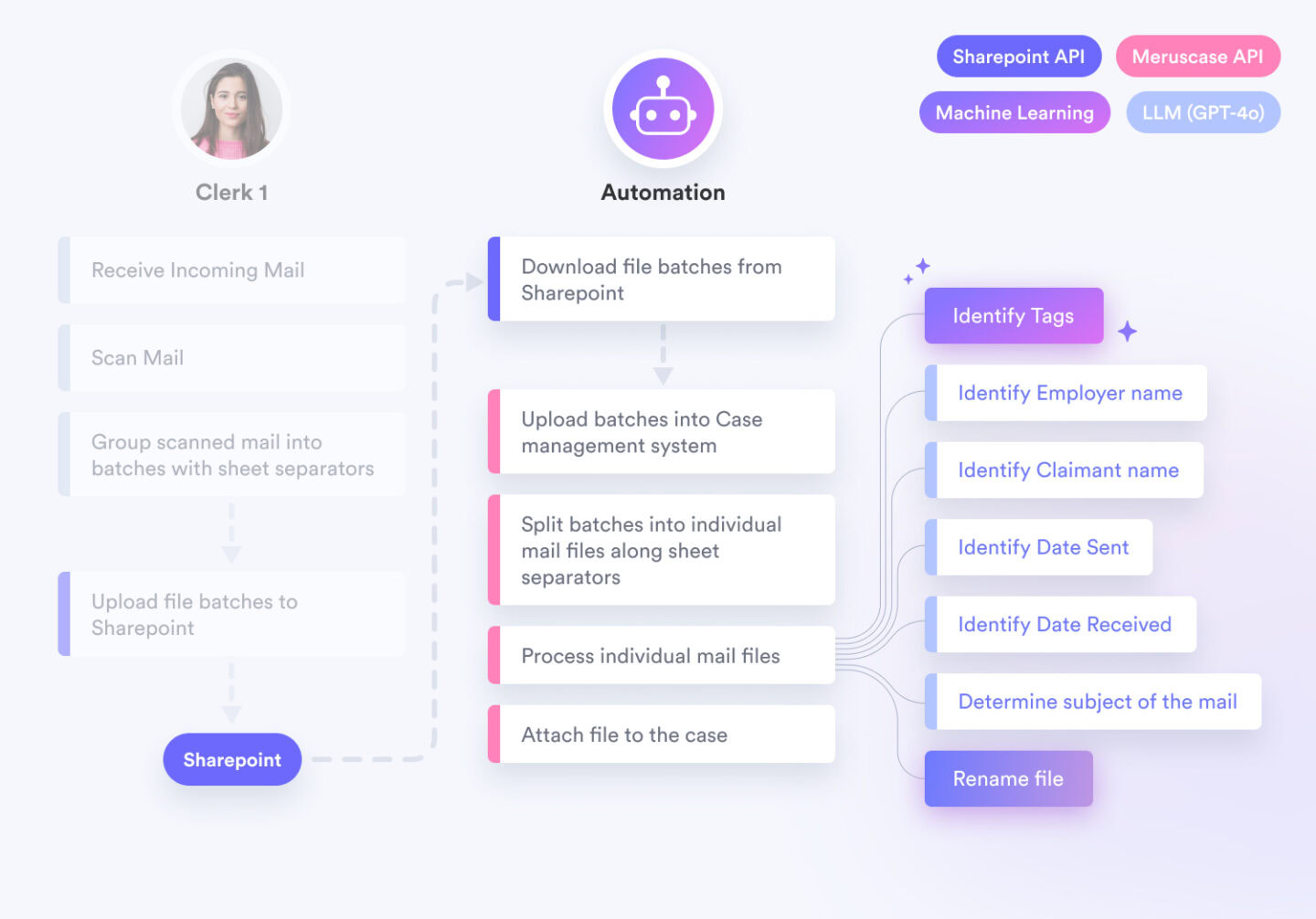
Business Benefits
Our automation solution delivered significant improvements:
1. Reduced manual labor by 80%
2. Automated processing of 300+ letters per day
3. 98% accuracy in document classification and information extraction
4. Enhanced attorney productivity by ensuring faster and more accurate document delivery
5. Reduced operational costs associated with mail processing
Reduced manual labor
80%
Letters processed daily
300+
Accuracy
98%
Technical Implementation
Our solution incorporates several advanced technologies:
1. Text Extraction/OCR for converting image versions of the scanned documents into text for further analysis
2. Machine Learning Models for document classification and file naming pattern recognition
3. Large Language Models (LLMs) for information extraction and template population
4. AWS Services for data storage, processing, and API interactions
5. Bubble.io for creating a user-friendly monitoring dashboard
Text Extraction (OCR)
The initial step in our process involves extracting text from scanned documents. The law firm uploads batches of scanned documents as PNG images to SharePoint. We implemented Tesseract, an open-source OCR engine, to convert these images into machine-readable text. To improve accuracy, especially for lower-quality scans, we applied noise reduction techniques before running the OCR process. This crucial step ensures that all subsequent text-based operations have high-quality input data.
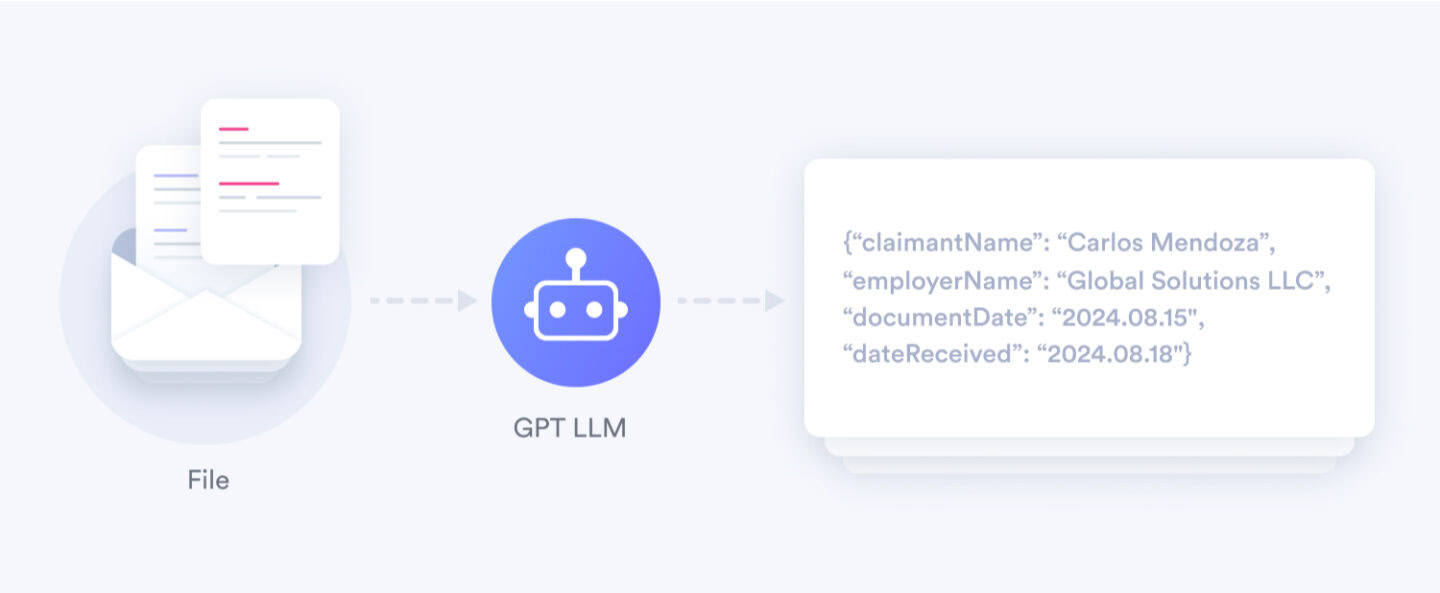
Information Extraction
We utilized a Large Language Model to recognize and extract essential information from documents, including:
- Document date
- Letter date
- Claimant’s name
- Employer’s name
Document Classification
We developed a neural network-based classification model trained on thousands of pre-classified documents from the client’s Meruscase system. This model accurately tags incoming documents, eliminating the need for manual classification.
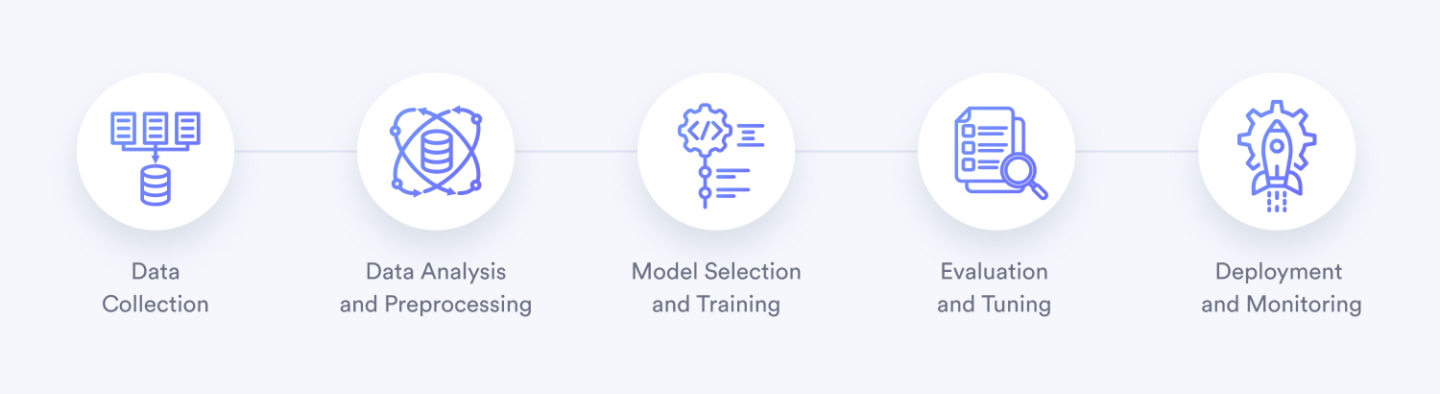
How we solved the Document Classification Problem:
1. Data Collection: We extracted thousands of pre-classified files from the client’s Meruscase system to create our training dataset.
2. Data Analysis and Preprocessing: We addressed issues such as duplicates, class imbalance, and outliers. Key preprocessing steps included lemmatization and categorical feature encoding.
3. Model Selection and Training: After experimenting with various algorithms, we chose a Fully Connected Neural Network (FCNN) due to its ability to handle complex nonlinear relationships in large datasets. The network uses ReLU activation for the first layer and sigmoid for the second layer.
4. Evaluation and Tuning: We assessed the model using metrics such as accuracy, recall, precision, and F1 score. Multiple experiments were conducted to optimize hyperparameters and improve performance.
5. Deployment and Monitoring: The model was integrated into the client’s system with continuous monitoring to track real-time performance and allow for ongoing improvements.
File Naming Automation
The principle of creating a file name pattern definition model is similar to that of a tag classification model. The key difference lies in the number of possible outcomes: while we had 25 tag options, the number of file naming patterns is much larger, exceeding a thousand. To address this challenge, there are two primary approaches:
- Increase the dataset with training data by thousands of times
- Reduce the number of patterns to 100-200
We chose the second approach and collaborated with the client team to reduce the number of unique patterns.
Process Automation
The entire workflow is automated and scheduled to run daily. We created a monitoring dashboard using Bubble.io, with data stored in an AWS MySQL database. Scripts run on AWS ECS, and services interact through a custom API.
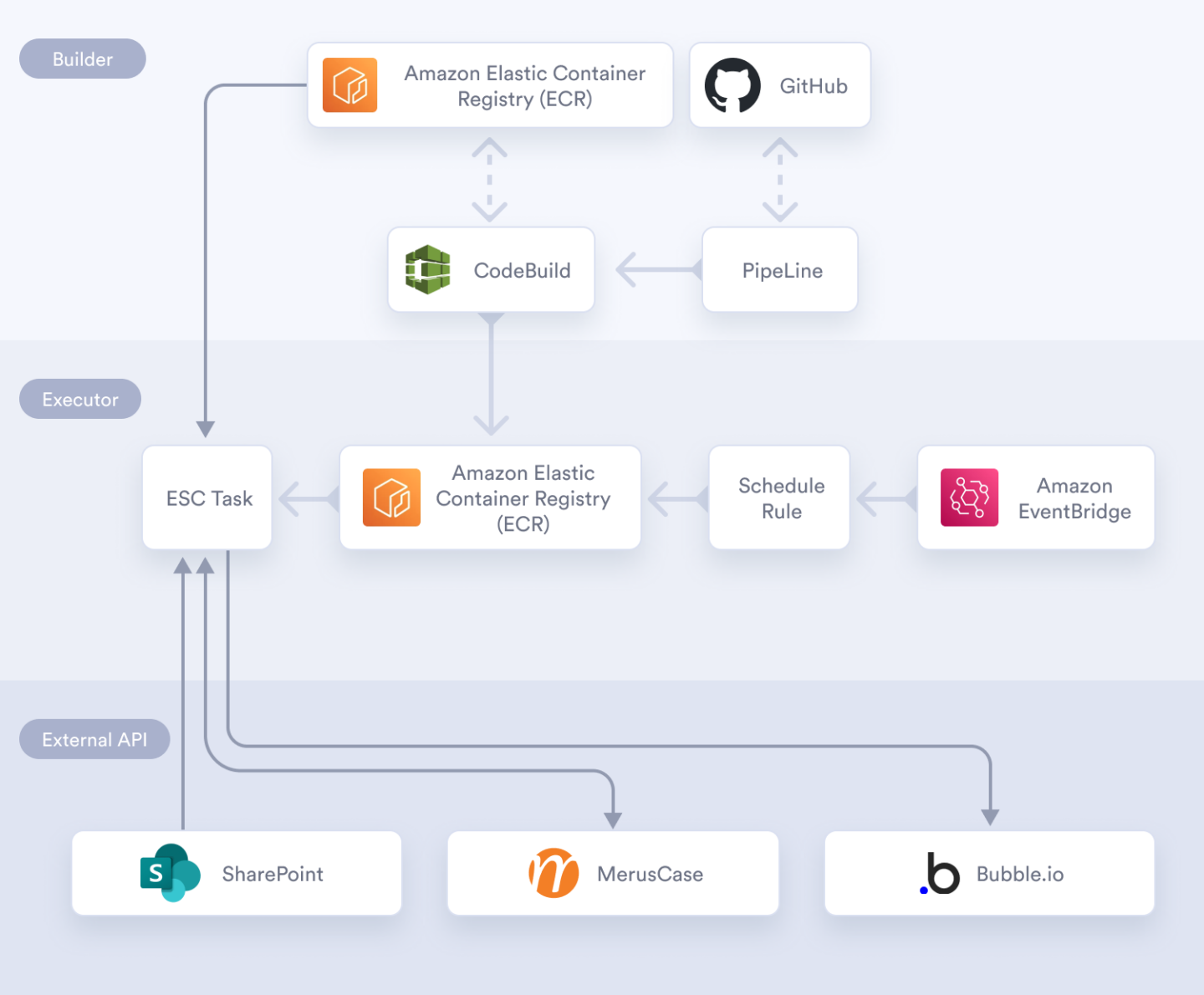
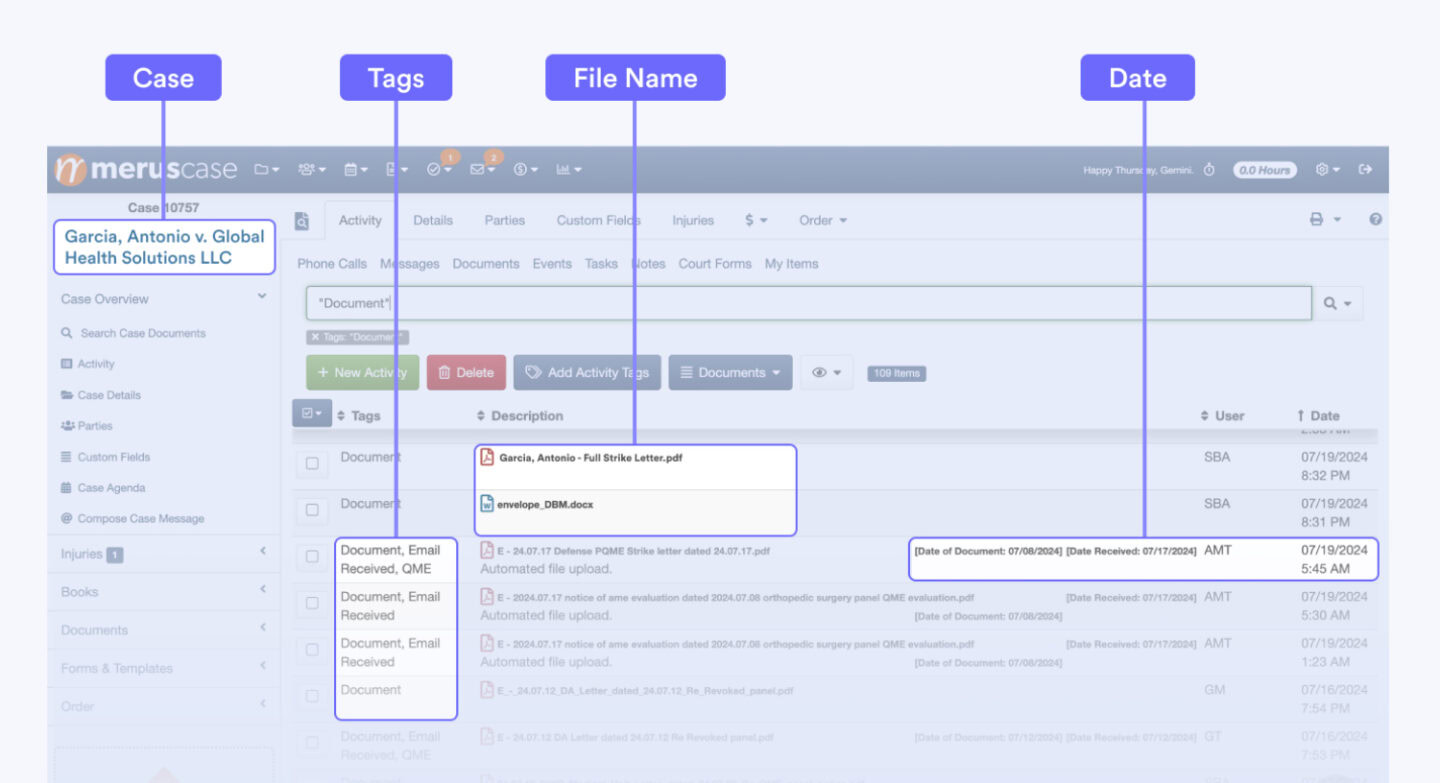
Process Monitoring and Dashboard
To ensure seamless operation and provide real-time insights, we developed a comprehensive monitoring dashboard using Bubble.io, a powerful no-code platform. This custom dashboard allows the law firm’s staff to monitor the status of each batch and individual file as it moves through the automated workflow.
Conclusion
By implementing this advanced automation solution, we have significantly enhanced the law firm’s document processing capabilities.
The system not only reduces manual labor and operational costs but also improves accuracy and speed in handling critical legal documents. As we continue to refine and expand the system’s capabilities, we anticipate even greater efficiencies and performance improvements in the future.
Transform Your Business with AI Automation
See how AI can enhance efficiency and reduce manual tasks. Let’s explore how automation can work for you.
Get in touch to start the conversation.